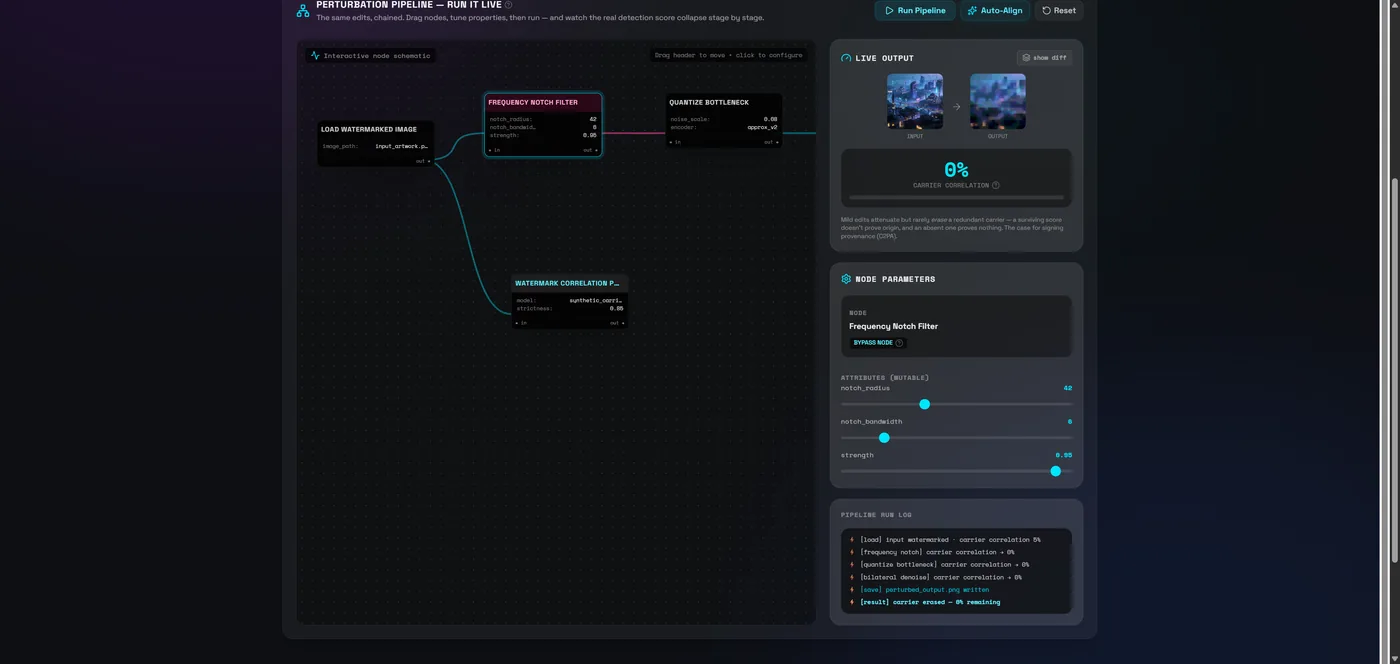
Abstract. AI content watermarking — the family Google DeepMind's SynthID belongs to — hides a recoverable signal inside generated images, text, and audio. This white paper shows, with a hands-on browser lab, that such in-band signals are fragile by construction: a frequency-notch filter, a denoise pass, a re-encode, or a paraphrase attenuates the mark while the asset still looks and reads fine — and the failure is silent. It argues that durable provenance must instead be cryptographically signed (C2PA / Content Credentials), where tampering breaks a signature visibly and "no provenance" becomes an explicit, auditable state.
- In the lab's synthetic carrier, a single frequency-notch pass can drop detection from ~100% to low single digits while PSNR stays above ~40 dB — the removal costs nothing visible.
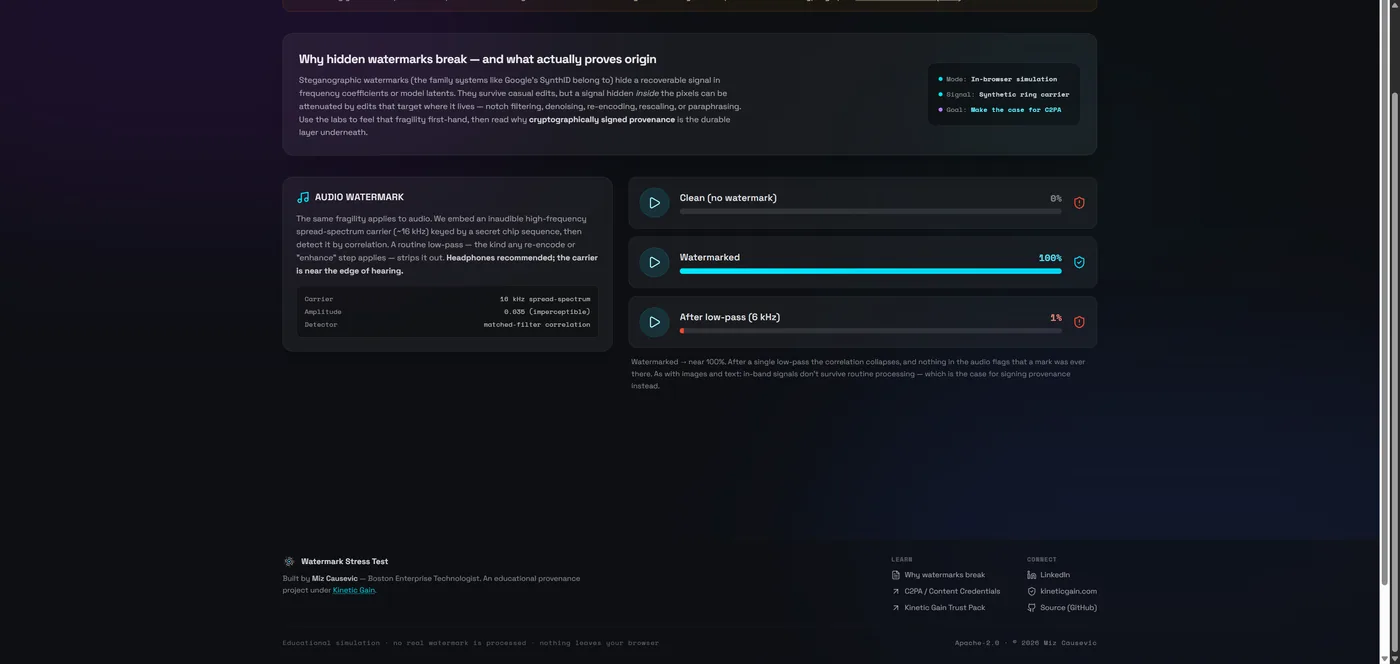
- The same fragility holds across modalities: a text watermark's Z-score resets toward chance under paraphrasing; an audio carrier reading 100% falls to ~1% after one low-pass.
- A stripped watermark is silent — absence proves nothing, so a low score never means "human-made."
- A C2PA signature does the opposite: after a simple re-save, the watermark still reads ~80% while the signature reads INVALID — tamper-evidence by design.
As AI-generated media became indistinguishable from the real thing, the obvious defence was to mark the output: hide an invisible, machine-recoverable signal in every generated image, audio clip, or paragraph so a detector could later say "a model made this." Google DeepMind's SynthID is the best-known example of this family. The idea is good, and the engineering is genuinely impressive. But it carries a structural limit that anyone relying on it for trust decisions needs to understand: a signal hidden inside the content can be weakened by edits that target where it lives.
This paper explains the mechanism in plain terms, shows the four edit classes that attenuate it across image, text, and audio, and argues for the layer that doesn't share the weakness — cryptographically signed provenance, standardised as C2PA and shipped to users as Content Credentials.
How content watermarking works
Images: a carrier hidden in the frequencies
An image watermark modulates the picture so the visible result is unchanged but a hidden pattern — a carrier — is present in the frequency coefficients or the model's latent representation. A detector holding a secret key correlates the image against the expected carrier and returns a confidence score. Crucially, it returns a probability, not a yes/no certificate. The carrier is engineered to be redundant and resilient so it survives JPEG compression, resizing, and colour tweaks.
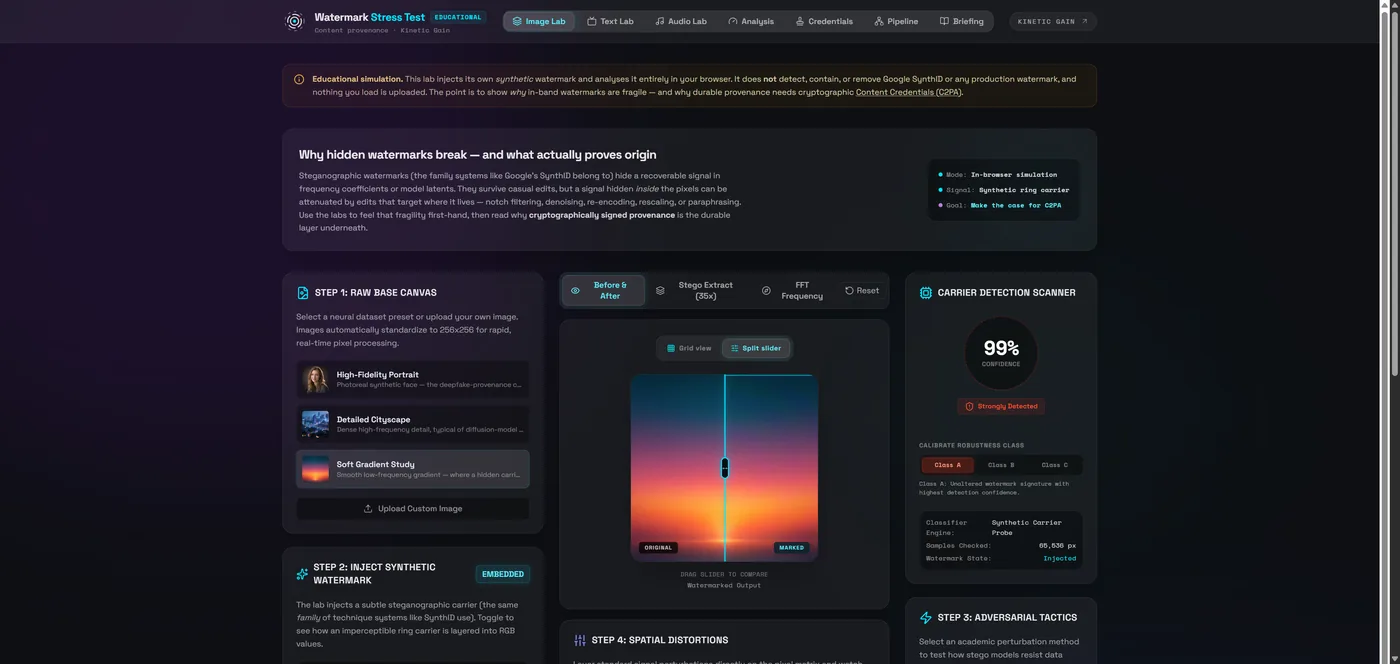
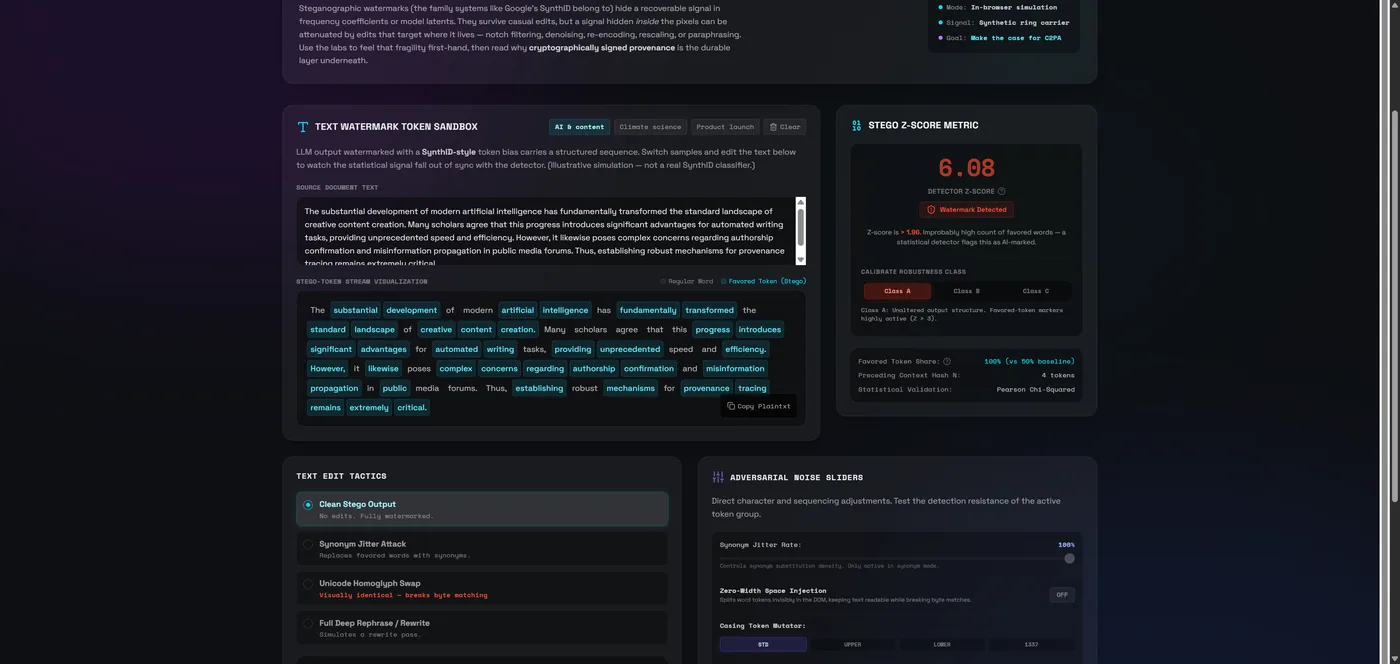
Text: a bias in word choice
Text watermarks work differently but rhyme. During generation the model splits its vocabulary into "favoured" and "neutral" tokens based on a hash of the preceding words, and nudges sampling toward favoured tokens. Watermarked text then contains a statistically improbable share of favoured tokens, detectable with a Z- or G-test over enough words. Again: a statistical signal, recoverable only while the text is intact.
Audio: the same story in sound
Audio watermarks embed an inaudible, spread-spectrum carrier keyed by a secret chip sequence, recovered with a matched filter. It is the same bargain as images and text: a low-amplitude signal riding inside ordinary content. In the lab, watermarked audio reads 100% — and a single routine low-pass at 6 kHz, the kind any re-encode applies, drops it to roughly 1%.
Why it's fragile: four ordinary edits
Robust does not mean unconditional. The same property that makes a watermark invisible — it's a low-amplitude signal riding inside ordinary content — is what makes it removable. In the lab you can watch each of these drive a synthetic carrier's detection score toward zero:
| Edit class | What it does | Why the carrier fades |
|---|---|---|
| Frequency notch | Attenuates a narrow radial band of the FFT spectrum | If the carrier sits in a predictable band, that band is filterable with little visible cost |
| Noise jitter | Adds low-amplitude broadband noise | Scrambles the fine pixel correlations a carrier depends on |
| Re-encode / quantize | Drops bit depth, downsamples, re-saves | Clips the micro-variations to the nearest grid step — often as an accidental side effect |
| Denoise | Edge-preserving smoothing (bilateral / NLM) | Treats the carrier as sensor noise and wipes it while keeping detail crisp |
For text the analogues are paraphrasing, synonym substitution, back-translation, and character-level swaps (homoglyphs, zero-width characters). Each breaks the context-hash chain and resets the favoured-token bias toward chance. The unifying theme: the mark is strongest exactly when the content is untouched, and weakest the moment anyone edits it — which is most of the real internet.
What this means for trust decisions
Two consequences follow directly, and both matter for anyone building governance, trust & safety, or content-authenticity workflows:
- A low score is not proof of human authorship. The carrier may simply have faded. Watermark absence is evidence of nothing.
- A stripped mark is silent. Nothing in the asset announces that a watermark was removed. The failure mode is invisible — the worst kind for an audit.
This is the structural ceiling of any in-band signal. It does not make watermarking useless — as a corroborating signal at population scale it is valuable. It makes watermarking insufficient as the foundation of a provenance claim. Regulators are already circling this gap: the EU AI Act's Article 50 transparency duties push synthetic-content disclosure toward "machine-readable and reliable," and a watermark-only answer does not survive the question "what does absence prove?" (General information, not legal advice.)
The durable fix: sign provenance, don't hide it
The alternative inverts the design. Instead of hiding a signal and hoping it survives, C2PA / Content Credentials attach cryptographically signed metadata — who created the asset, with what tool, through what edits — and bind it to the content with a tamper-evident manifest. The properties are the mirror image of watermarking's weaknesses:
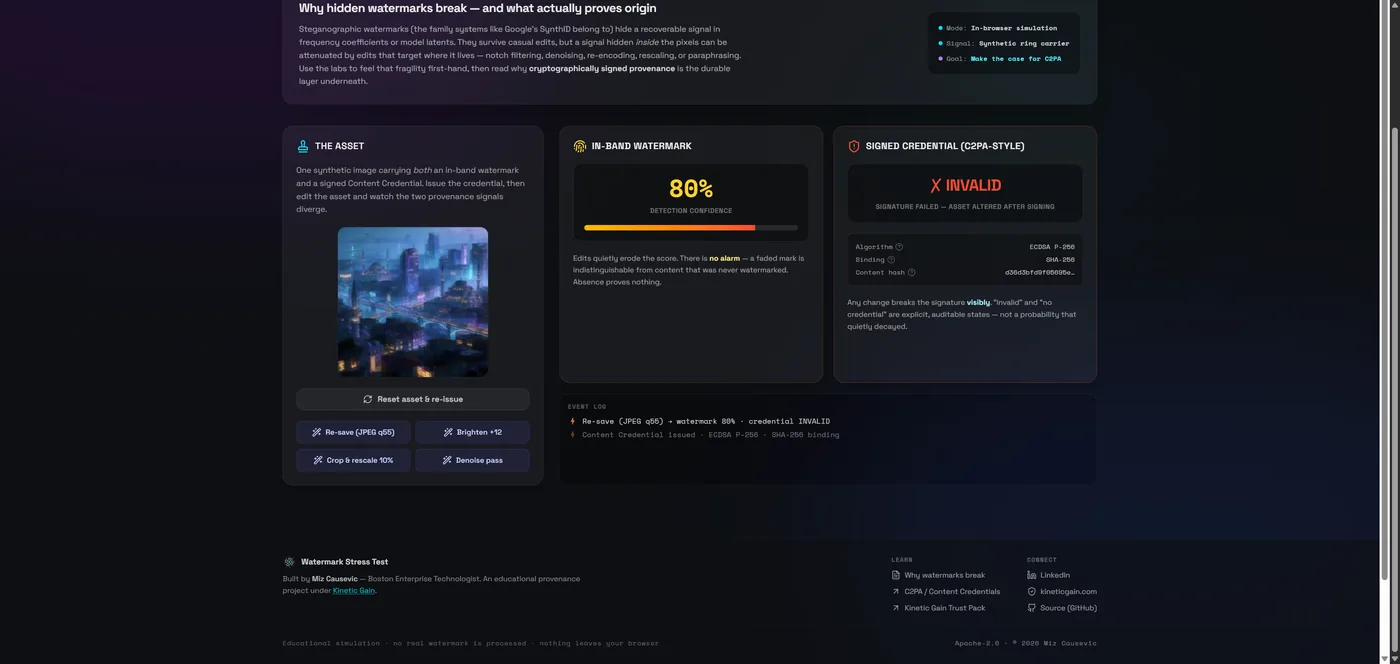
| In-band watermark | Content Credentials (C2PA) | |
|---|---|---|
| Detection result | Probability (can fade) | Valid / invalid / absent (explicit) |
| Tampering | Silent attenuation | Signature fails — visibly |
| "No signal" means | Nothing provable | No verifiable provenance — a checkable state |
| Best role | Corroborating signal | Foundation of the claim |
A broken or missing credential is an explicit, auditable state — the difference between "we couldn't detect a watermark" and "this asset carries no valid provenance." That auditability is what governance actually needs.
See it for yourself
Reading that watermarks are fragile is one thing; watching a detection gauge fall to zero under a notch filter you control is another. The lab lets you inject a synthetic carrier, see it in the FFT, and attenuate it with real signal-processing filters — plus a text sandbox that resets a Z-score with synonym and character edits, an audio lab, and a Web-Crypto credential demo that signs and verifies with ECDSA P-256.
Frequently asked questions
Are AI image and text watermarks reliable for proving origin?
They're robust against many casual transformations but fragile against targeted edits — frequency filtering, denoising, re-encoding, rescaling, paraphrasing, character substitution. Detection returns a probability, not a certificate, so a low or absent score never proves content is human-made. Treat watermarking as one corroborating signal, not proof.
What's the difference between watermarking and Content Credentials?
Watermarking hides a recoverable signal inside the media; if it fades or is stripped, the loss is silent. C2PA attaches cryptographically signed provenance to the asset, so tampering breaks the signature visibly. One is probabilistic and in-band; the other is auditable and tamper-evident.
Does watermarking satisfy AI transparency rules like the EU AI Act?
Article 50 pushes toward machine-readable disclosure of synthetic content. A watermark-only answer is brittle because the absence of a watermark proves nothing — the gap signed Content Credentials are designed to close. This is general information, not legal advice.
Does the lab remove real watermarks like SynthID?
No. It operates only on a synthetic watermark it injects itself, in your browser. The robustness point is general: in-band watermarks can be attenuated by ordinary editing, which is why provenance shouldn't depend on them alone.
Related work
This project concerns content provenance watermarking — marks embedded in generated media (the SynthID family). It is independent of, and not derived from, the Watermark-Robustness-Toolbox (WRT) by Lukas, Jiang, Li & Kerschbaum, which benchmarks the robustness of DNN model-weight watermarks — used to prove ownership of trained neural networks, a distinct subfield. See their IEEE S&P 2022 paper, "SoK: How Robust is Deep Neural Network Image Classification Watermarking?" Different domain, different stack, no shared code.